c语言
简单有效
BAT批量重命名
文学
csdn云IDE
easyui
rknn
xid
人手检测
ps
web课程与设计
随机森林
plugin
机场调度管理系统
Scratch编程
webdav
bypassav
go入门教程
ai
期货择时
正则化
2024/4/12 4:02:40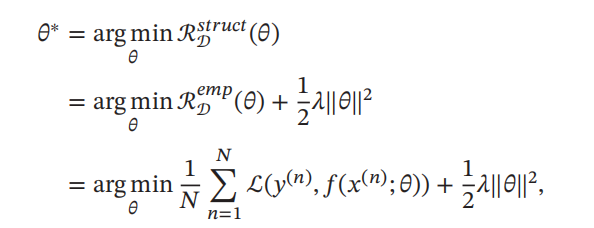
机器学习的学习准则(期望风险最小化、经验风险最小化、结构风险最小化)
训练集是有N个独立同分布的样本组成,即每个样本(x,y)是独立的从相同的分布中抽取的。这个真实的分布未知
输入空间X和输出空间Y构成样本空间,对于样本空间中的样本(x, y)∈X x Y,假定x和y之间可通过一个未知的真实隐射yg(x)来描述࿰…

julia_Julia的分区错误
juliadiv() function is used to divide for the integer division, by using this function we can get exception/error at two cases, div()函数用于除以整数除法,通过使用此函数,我们可以在两种情况下获得异常/错误, Dividing an intege…

欠拟合、过拟合、正则化、学习曲线
1.欠拟合、过拟合、正则化、学习曲线
1.1 欠拟合、过拟合
欠拟合:模型相对于要解决的问题来说太简单了,模型并没有拟合训练数据的状态 过拟合:模型相对于要解决的问题来说太复杂了,模型只能拟合训练数据的状态
下图来自&#x…

牛客网算法八股刷题系列(七)正则化(软间隔SVM再回首)
牛客网算法八股刷题系列——正则化[软间隔SVM再回首]题目描述正确答案:C\mathcal CC题目解析开端:关于函数间隔问题解释的补充软间隔SVM\text{SVM}SVMHinge\text{Hinge}Hinge损失函数支持向量机的正则化题目描述
关于支持向量机(Support Vector Machine…
减少过拟合:权重衰减
我们来审视一下过拟合出现的原因:
小模型容易欠拟合,大模型容易过拟合,也就是说参数越多、模型容量越大,过拟合越容易产生(理论上)。
之所以这样,是因为模型的优化总是向着使训练损失更小的方…

机器学习笔记之正则化(二)权重衰减角度(直观现象)
机器学习笔记之正则化——权重衰减角度[直观现象]引言回顾:拉格朗日乘数法角度观察正则化过拟合的原因:模型参数的不确定性正则化约束权重的取值范围L1L_1L1正则化稀疏权重特征的过程权重衰减角度观察正则化场景构建权重衰减的描述过程权重衰减与过拟合…
深入理解深度学习——正则化(Regularization):参数绑定和参数共享
分类目录:《深入理解深度学习》总目录 目前为止,我们讨论对参数添加约束或惩罚时,一直是相对于固定的区域或点。例如, L 2 L^2 L2正则化(或权重衰减)对参数偏离零的固定值进行惩罚。然而,有时我…

机器学习实战——基于Scikit-Learn和TensorFlow 阅读笔记 之 第十一章:训练深度神经网络
《机器学习实战——基于Scikit-Learn和TensorFlow》
这是一本非常好的机器学习和深度学习入门书,既有基本理论讲解,也有实战代码示例。
我将认真阅读此书,并为每一章内容做一个知识笔记。
我会摘录一些原书中的关键语句和代码,若有…

【机器学习基础】正则化
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战 欢迎订阅&am…

人工智能基础_机器学习022_使用正则化_曼哈顿距离_欧氏距离_提高模型鲁棒性_过拟合_欠拟合_正则化提高模型泛化能力---人工智能工作笔记0062
然后我们再来看一下,过拟合和欠拟合,现在,实际上欠拟合,出现的情况已经不多了,欠拟合是
在训练集和测试集的准确率不高,学习不到位的情况.
然后现在一般碰到的是过拟合,可以看到第二个就是,完全就把红点蓝点分开了,这种情况是不好的,
因为分开是对训练数据进行分开的,如果来…

权重衰减 vs L2正则
避免过拟合的方法有很多:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)包括L1、L2(L2 regularization也叫weight decay),dropout。
这里重点讲解 L2正则…

机器学习(二):模型评估与模型选择、正则化与交叉验证、L0,L1,L2正则化、泛化能力
训练误差与测试误差
机器学习的目的是使学习到的模型不仅对已知数据而且对未知数据都能有很好的预测能力。不同的学习方法会给出不同的模型。当损失函数给定时, 基于损失函数的模型的训练误差(training error) 和模型的测试误差(…

神经网络常用归一化和正则化方法解析(二)
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…

机器学习--模型复杂度及正则化
逻辑回归会倾向于学习到ω\omegaω最大的值,怎么解决这个问题
在损失函数中引入正则项: L(θ)∑i1Nyilog(11exp(−ωTx))(1−yi)log(exp(−ωTx)1exp(−ωTx)12λω2L(\theta) \sum_{i1}^N y_{i}log(\frac{1}{1\exp(-\omega^Tx)})(1-y_{i})log(\…

正则化(L1和L2范数)
说实话,这么后才来写正则化是挺奇怪的。
相信大家都知道损失函数,是用来描述我们模型与训练数据之间的差距(即是否能准确拟合训练数据)。但其实我们真正在实战用的是目标函数。目标函数的构造是:损失函数正则化。 参考…

神经网络优化-正则化DropOut
实现正则化主要需要在两个地方做出修改:
1.cost计算(L2 regularization) #正则化n len(parameters)//2cost_extra 0for x in range(n):w parameters[wstr(x1)]cost_extra np.sum(np.multiply(w,w))cost_extranp.squeeze(cost_extra)cost…

【机器学习】支持向量机(下)
支持向量机(下) 目录 八、支持向量机的求解实例九、核函数1、核函数的引入2、核函数的示例 十、软间隔1、何为软间隔2、引入软间隔后的目标方程 十一、正则化十二、关于支持向量机的分类十三、数据标准化的影响【机器学习】支持向量机(上&…
第二章:消费、储蓄和投资_几何途行_新浪博客
消费、储蓄和投资 影响居民个人或家庭消费的因素: 1.收入水平 2.消费品的价格水平 3.消费者个人的偏好 4.消费者对其未来收入的预期 5.消费信贷及其利率水平 消费倾向:考虑的是消费与收入的比率问题 C代表消费,Y代表收入Cc(Y)࿱…

机器学习之正则化(机器学习基石)
正则化的目标
在机器学习问题中有时会由于资料量太少、有杂讯或者是学习模型的复杂度太高会导致一种Ein≈0(样本内的错误率)但是Eout(实际估计中的错误率)很高的现象这种现象就叫过拟合(详情请点击打开链接了解过拟合&…

9 正则化概述 --机器学习基础理论入门
9 正则化概述 --机器学习基础理论入门
9.1 模型过拟合问题
过拟合的概念:
过拟合就是训练出来的模型在训练集上表现很好,但是在测试集上表现较差的一种现象。 图1欠拟合,图3过拟合
模型出现过拟合的原因
(1) 数据…
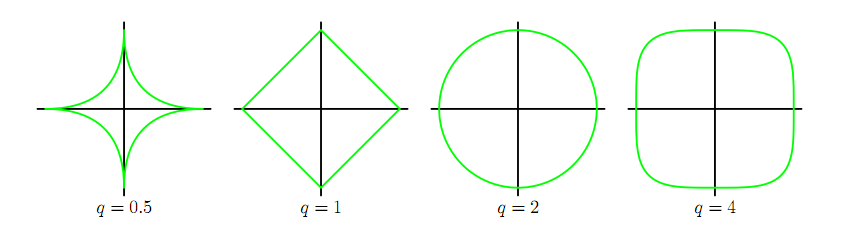
机器学习中的正则化技术L0,L1与L2范数
本文转载自https://blog.csdn.net/weiyongle1996/article/details/78161512。 使用机器学习算法过程中,如果太过于追求准确率,就可能会造成过拟合。使用正则化技术可以在一定程度上防止过拟合。首先来回顾一下过拟合的概念。
过拟合简单来说就是对于当前…
正则化:优化模型的秘密武器
正则化:优化模型的秘密武器
大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,让我们一同深入探讨机器学习中的重要主题——正则化。
1. …

激活函数,损失函数,正则化
激活函数简介
在深度学习中,输入值和矩阵的运算是线性的,而多个线性函数的组合仍然是线性函数,对于多个隐藏层的神经网络,如果每一层都是线性函数,那么这些层在做的就只是进行线性计算,最终效果和一个隐藏…

机器学习-白板推导系列(三)-线性回归
3. 线性回归 本章内容: 1、最小二乘法(矩阵表达与几何意义) 2、概率角度:最小二乘法⇔noise为Gaussian的MLE(最大似然估计)最小二乘法\Leftrightarrow noise为Gaussian 的 MLE(最大似然估计&…
机器学习和深度学习中,L2正则化为什么能防止过拟合?
正则化是为了降低模型的复杂度,模型过于复杂,则过拟合;
与傅里叶变换类似,高频的部分表示细节,尽量减少高频部分的影响;
傅里叶级数也是,高阶表示细节;
当阶数较高时,…

5328笔记 Advanced ML Chapter7-Learning with Noisy Data
第二行,最左边第一张图是高斯噪点,第二张是椒盐噪点,第三张是块噪点block noise。 下边右边,是由于人的动作因素或者眼睛等环境因素,造成的噪点。 Large noise是outlier,它们的数据和我们的数据本身分布已…
SVM支持向量机-软间隔与松弛因子(3)
上一篇文章推导SMO算法时,我们通过导入松弛因子,改变了对偶问题的约束条件,这里涉及到软间隔和正则化的问题,我们一直假定训练样本是完美无缺的,样本在样本空间或特征空间一定是线性可分的,即存在一个超平面…
![[深度学习]更好地理解正则化:可视化模型权重分布](https://img-blog.csdn.net/2018080819032974?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3l1d2VpbWluZzcw/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[深度学习]更好地理解正则化:可视化模型权重分布
在机器学习中,经常需要对模型进行正则化,以降低模型对数据的过拟合程度,那么究竟如何理解正则化的影响?本文尝试从可视化的角度来解释其影响。
首先,正则化通常分为三种,都是在loss函数的基础上外加一项: …
第五章.与学习相关技巧—正则化,超参数
第五章.与学习相关技巧 5.4 正则化&超参数
在机器学习中,过拟合是一个很常见的问题。过拟合指的是只能拟合训练数据,但不能很好的拟合不包含在训练数据中的其他数据状态。 1.发生过拟合的原因
模型拥有大量参数,表现力强。训练数据少。…
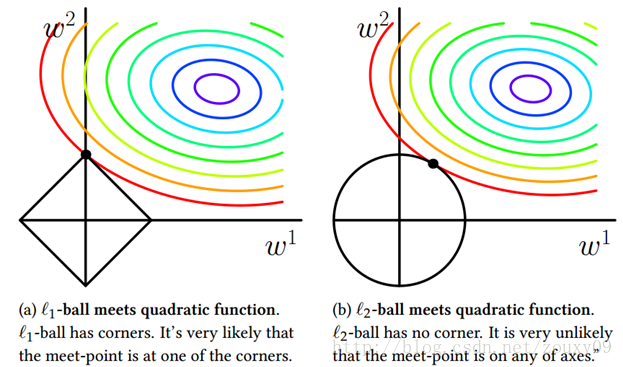
L0、L1与L2范数各自功能
机器学习中的范数规则化之(一)L0、L1与L2范数
zouxy09qq.com
http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化。我们先简单的来理解下常用的L0、L1、L2和核范数规则化。最后聊下规则化项参数的选…
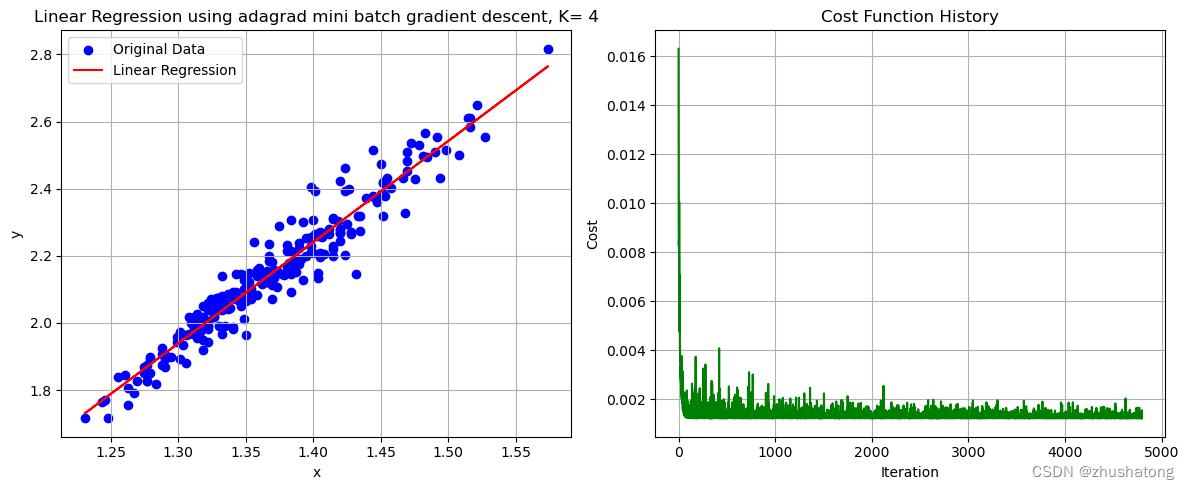
【机器学习】梯度下降法:从底层手写实现线性回归
【机器学习】Building-Linear-Regression-from-Scratch 线性回归 Linear Regression0. 数据的导入与相关预处理0.工具函数1. 批量梯度下降法 Batch Gradient Descent2. 小批量梯度下降法 Mini Batch Gradient Descent(在批量方面进行了改进)3. 自适应梯度…
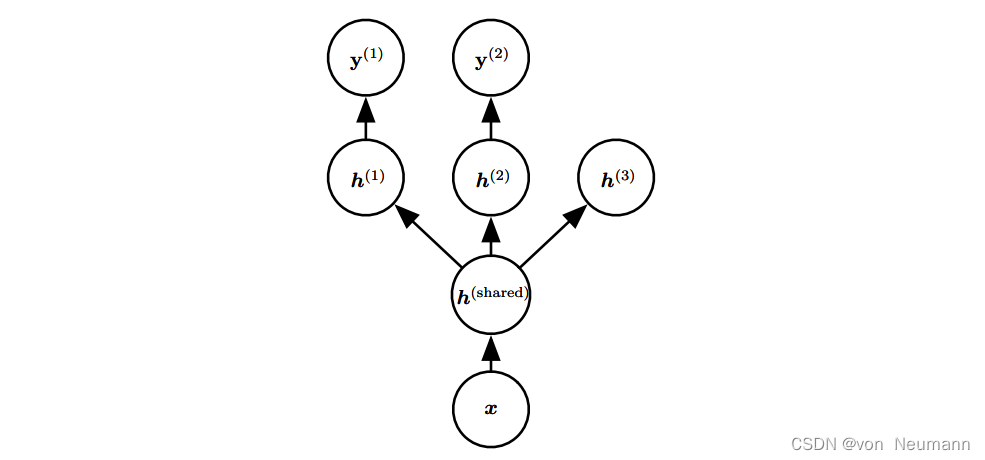
入理解深度学习——正则化(Regularization):多任务学习
分类目录:《深入理解深度学习》总目录 多任务学习是通过合并几个任务中的样例(可以视为对参数施加的软约束)来提高泛化的一种方式。正如额外的训练样本能够将模型参数推向具有更好泛化能力的值一样,当模型的一部分被多个额外的任务…

5328笔记 Advanced ML Chapter6-Sparse Coding and Regularisation
D是Overcompleteness过度完备的 R是Sparsity稀疏的 为什么要稀疏编码,我个人认识是让D尽可能的汇聚更多的信息,它就是一本字典,所以它的信息的超完备的,R是一种检索方式,越稀疏,检索的越快,就好…

吴恩达机器学习4--正则化(Regularization)
过拟合问题
看下面回归的例子 第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质。而中间的模型似乎最合适 在分类问题中&#x…
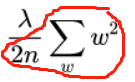
权重衰减(weight decay)
L2 正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫 L2 正则化。
参考:
https://blog.csdn.net/weixin_44936889/article/details/103705435https://microstrong.blog.csdn.net/article/deta…

机器学习笔记 - 数据科学中基于 Scikit-Learn、Tensorflow、Pandas 和 Scipy的7种最常用的特征工程技术
一、概述 特征工程描述了制定相关特征的过程,这些特征尽可能准确地描述底层数据科学问题,并使算法能够理解和学习模式。换句话说:您提供的特征可作为将您自己对世界的理解和知识传达给模型的一种方式。 每个特征描述一种信息“片段”。这些部分的总和允许算法得出有关目标变…
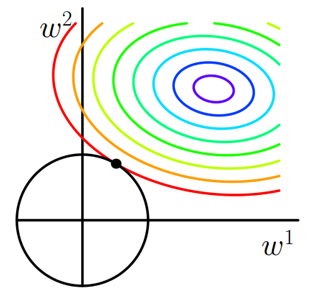
为什么正则化能够解决过拟合问题?
为什么正则化能够解决过拟合问题一. 正则化的解释二. 拉格朗日乘数法三. 正则化是怎么解决过拟合问题的1. 引出范数1.1 L_0范数1.2 L_1范数1.3 L_2范数2. L_2范式正则项如何解决过拟合问题2.1 公式推导2.2 图像推导[^2]2.2.1 L1正则化2.2.2 L2正则化四. 结论如果觉得不想看前两…

2020春秋招聘 人工智能方向 各大厂面试常见题整理二(附答案)(阿里腾讯华为字节)
喜欢的话请关注我们的微信公众号~《你好世界炼丹师》。
公众号主要讲统计学,数据科学,机器学习,深度学习,以及一些参加Kaggle竞赛的经验。公众号内容建议作为课后的一些相关知识的补充,饭后甜点。此外,为了…

Keras - Dropout 理论与实践
一.引言 Dropout 层用于解决过拟合的问题,当原始样本偏少而深度模型参数偏多时,模型偏向于学习一些极端的特征从而导致过拟合,在训练样本上达到很高的精度但在测试集的表现却很糟糕,这时候可以引入 Dropout 按适当的比例舍弃掉一些…
CGAL 建筑物轮廓规则化(二维)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 假设给定一组由线段连接的有序二维点,这些点构成一个闭合或开放的轮廓,CGAL中提供了三种方式来实现多边形轮廓的规则化: 平行:将检测到的接近平行的轮廓边缘完全平行。正交性:将检测到接近正交的轮廓边缘,使其完…
正则化与L0,L1,L2范数简介
参考:机器学习中的范数规则化之(一)L0、L1与L2范数
1. 常见的范数
1.1 L0 范数
向量中非零元素的个数,即稀疏度,适合稀疏编码,特征选择。
1.2 L1 范数
又叫曼哈顿距离或最小绝对误差,向量中…
【机器学习】从贝叶斯角度理解正则化缓解过拟合
从贝叶斯角度理解正则化缓解过拟合
参考: LR正则化与数据先验分布的关系? - Charles Xiao的回答 - 知乎
原始的Linear Regression
假设有若干数据 (x1,y1),(x2,y2),...,(xm,ym),我们要对其进行线性回归。也就是得到一个方程 yωTxϵ注意,…
线性代数中的正则化(regularization)(zz)
正则化(regularization)在线性代数理论中,不适定问题通常是由一组线性代数方程定义的,而且这组方程组通常来源于有着很大的条件数的不适定反问题。大条件数意味着舍入误差或其它误差会严重地影响问题的结果。反问题有两种形式。最普遍的形式是已知系统和…
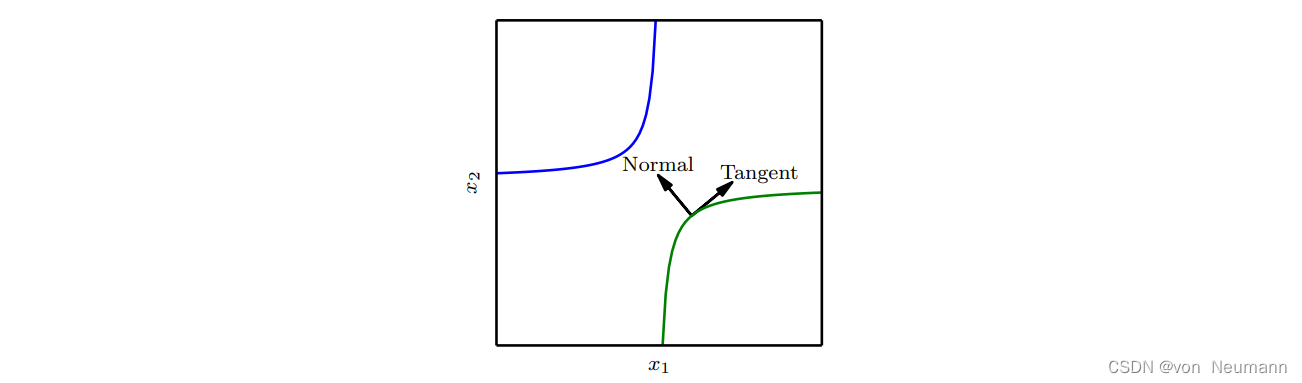
深入理解深度学习——切面距离(Tangent Distance)、正切传播(Tangent Prop)和流形正切分类器
分类目录:《自然语言处理从入门到应用》总目录 许多机器学习通过假设数据位于低维流形附近来克服维数灾难。一个利用流形假设的早期尝试是切面距离(Tangent Distance)算法 (Simard。它是一种非参数的最近邻算法,其中使用的度量不是…

李宏毅机器学习——学习笔记(2)
Regression
每类特定的参数值构成一个特定的function,所有的参数可取值构成的集合,就是一个function set.loss function的输入是模型的一个特定function, 输出是loss值。
Gradient Descent 梯度下降的方法可以求解任意的loss function&…

机器学习正则化、偏差和误差理解总结
2018-08-21更新:考虑用ensemble方法降低模型bias 和 variance
偏差:即模型在训练时候,衡量模型拟合程度的变量,训练期间拟合的越好,偏差越小,通常也会使得模型变得越复杂。但是,并不是偏差越小…
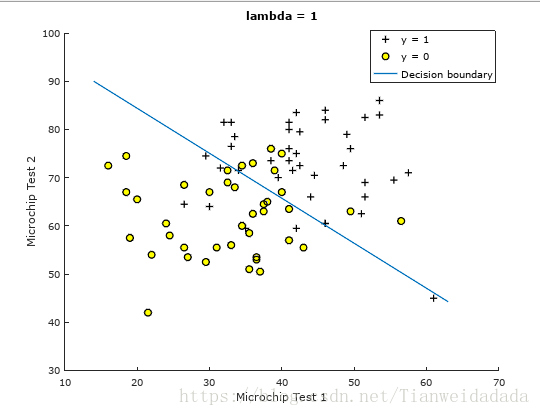
机器学习 LogsticRegression 正则化(matlab实现)
仍然使用之前的根据学生两学期分数,预测录取情况
主程序:
X load(ex4x.dat);
y load(ex4y.dat);
plotData(X,y);
[m,n] size(X);
X [ones(m,1),X];
lambda 1;
%[cost,grad] costFunction(theta,X,y,lambda);
%fprintf(Cost at initial theta (zero…
深入理解深度学习——正则化(Regularization):Bagging和其他集成方法
分类目录:《深入理解深度学习》总目录 相关文章: 集成学习(Ensemble Learning):基础知识 集成学习(Ensemble Learning):提升法Boosting与Adaboost算法 集成学习(Ensem…
【交叉熵损失函数】关于交叉熵损失函数的一些理解
目录0. 前言1.损失函数(Loss Function)1.1 损失项1.2 正则化项2. 交叉熵损失函数2.1 softmax2.2 交叉熵0. 前言
有段时间没写博客了,前段时间主要是在精读一些计算机视觉的论文(比如yolov1),以及学cs231n这…
leetCode 125. 验证回文串 + 双指针
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。字母和数字都属于字母数字字符。给你一个字符串 s,如果它是 回文串 ,返回 true ;否则࿰…

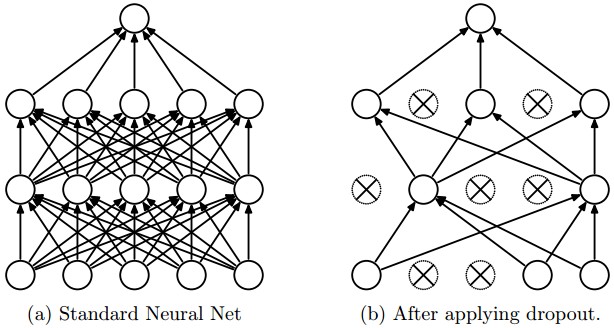
深度学习与计算机视觉系列(7)_神经网络数据预处理,正则化与损失函数
作者:寒小阳 && 龙心尘 时间:2016年1月。 出处: http://blog.csdn.net/han_xiaoyang/article/details/50451460 http://blog.csdn.net/longxinchen_ml/article/details/50451493 声明:版权所有,转载请联系…
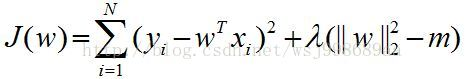
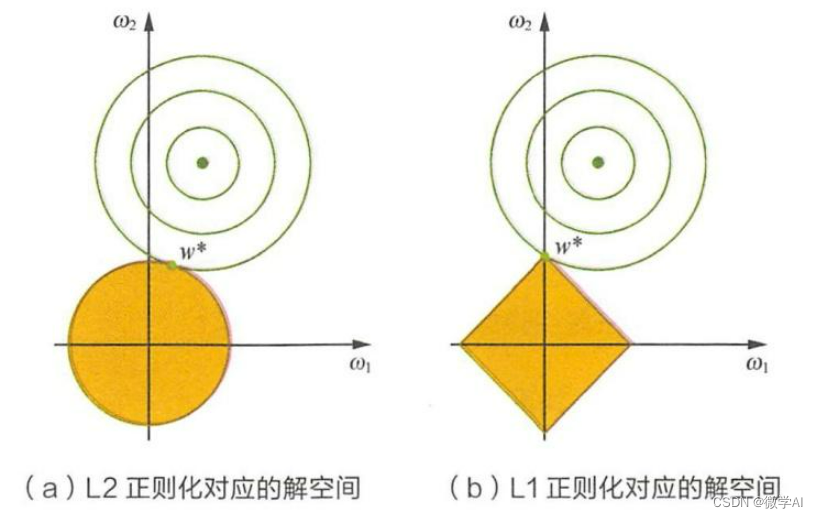
深度学习技巧应用35-L1正则化和L2正则在神经网络模型训练中的应用
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用35-L1 正则化和L2正则在神经网络模型训练中的应用。L1正则化和L2正则化是机器学习中常用的两种正则化方法,用于防止模型过拟合并提高模型的泛化能力。这两种正则化方法通过在损失函数中添加惩罚项来控制模型的复杂性。…
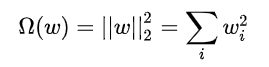
【标准化方法】(3) Group Normalization 原理解析、代码复现,附Pytorch代码
今天和各位分享一下深度学习中常用的标准化方法,Group Normalization 数据分组归一化,向大家介绍一下数学原理,并用 Pytorch 复现。
Group Normalization 论文地址:https://arxiv.org/pdf/1803.08494.pdf 1. 原理介绍
在目标检测…
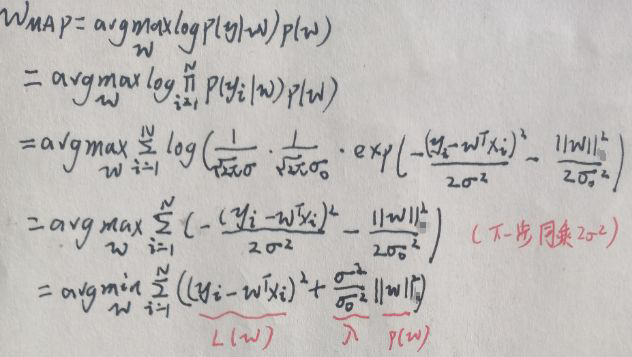
机器学习-白板推导-系列(三)笔记:线性回归最小二乘法与正则化岭回归
文章目录0 笔记说明1 最小二乘法求线性回归模型2 几何意义2.1 平方损失函数的几何意义2.2 用几何意义求线性回归模型3 从概率视角看最小二乘法4 正则化方法:岭回归4.1 频率角度4.2 贝叶斯角度5 总结0 笔记说明
来源于【机器学习】【白板推导系列】【合集 1…