一、XML映射文件是啥
前面我们学过了在Mapper接口用@注解的方式来操作sql语句
那么XML映射文件就另一种操作sql语句的方法
为什么还要有这么个玩意?
我简单说就是:如果有的sql特别复杂的话,比如需要【动态sql】的话,就得用到XML映射文件(这里的【动态sql】不是简单动态传几个参数,而是动态拼接where后面的条件......我下一篇会讲到);
当然@注解也是一种很方便的方法,没有哪个更好,你想用哪个就用哪个,只要记住【动态sql】要用XML映射文件
二、怎么用
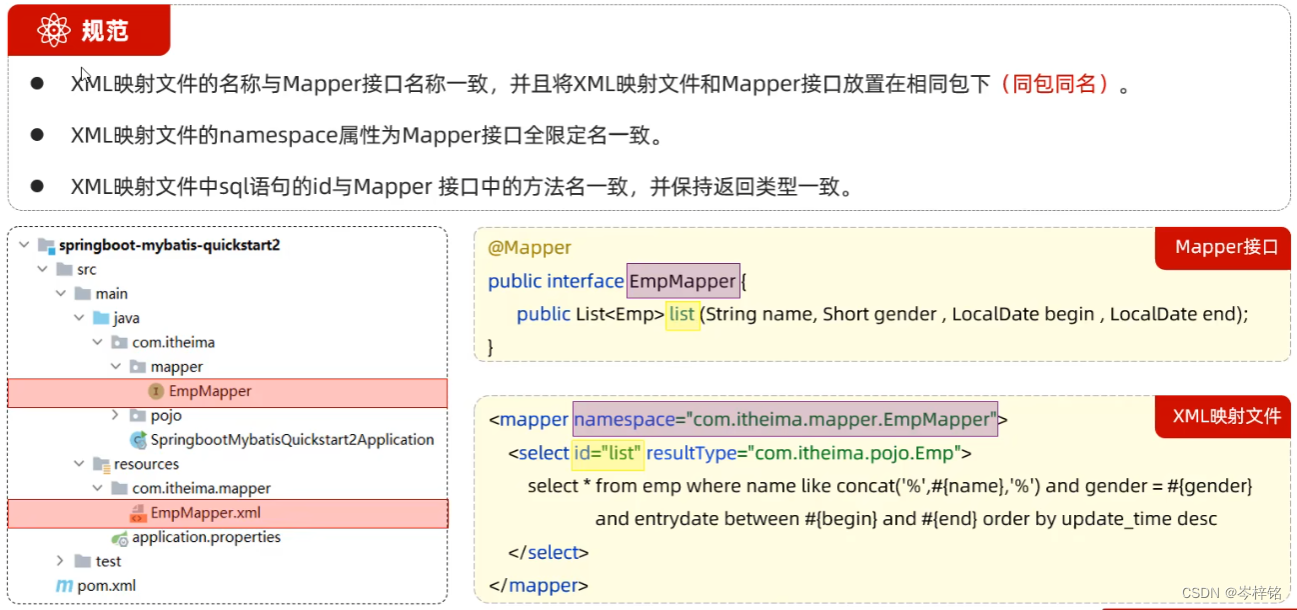
1、规范要求
配置XML文件得规范如下:必须按这个要求一步一步来
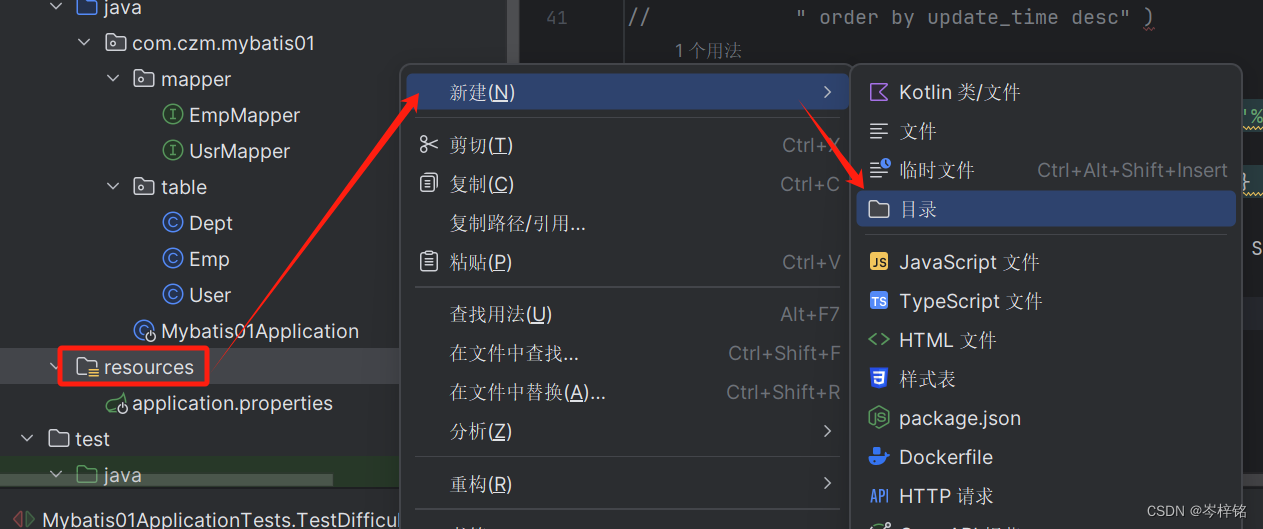
2、配置同包同名文件
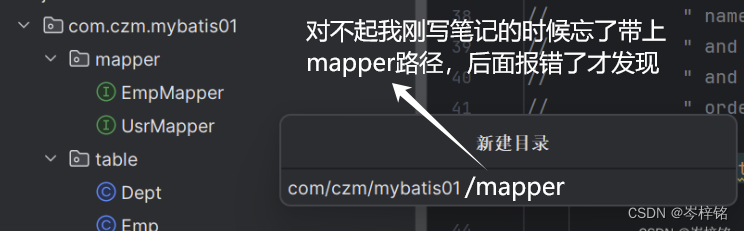
首先来到【resources】资源包,右键新建一个跟放我们Mapper目录的包的【同名字包】
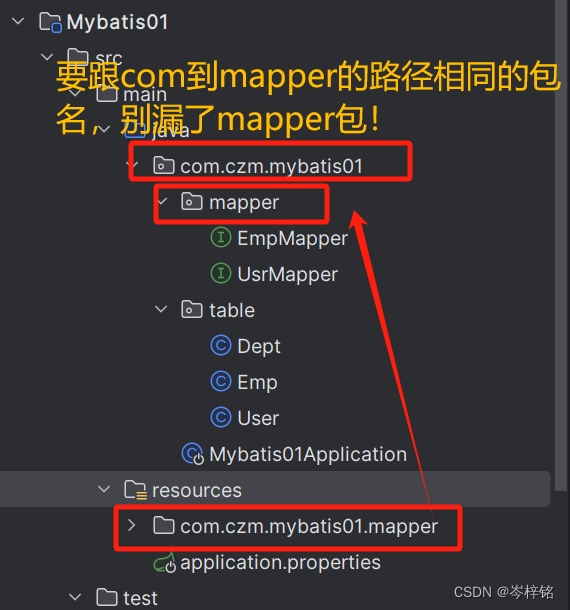
但是注意了!!!
之前我们创包为了图方便,直接新建一个【类】或者一个【接口】的同时,通过xxx.xxx.xxx这样的形式把各级的目录都创建好了
但是现在这里在这个目录起名的时候不能这样,因为这样只会生成一个叫《xxx.xxx.xxx》的文件夹


要采用 “/” 的路径分割法,xxx/xxx/xxx

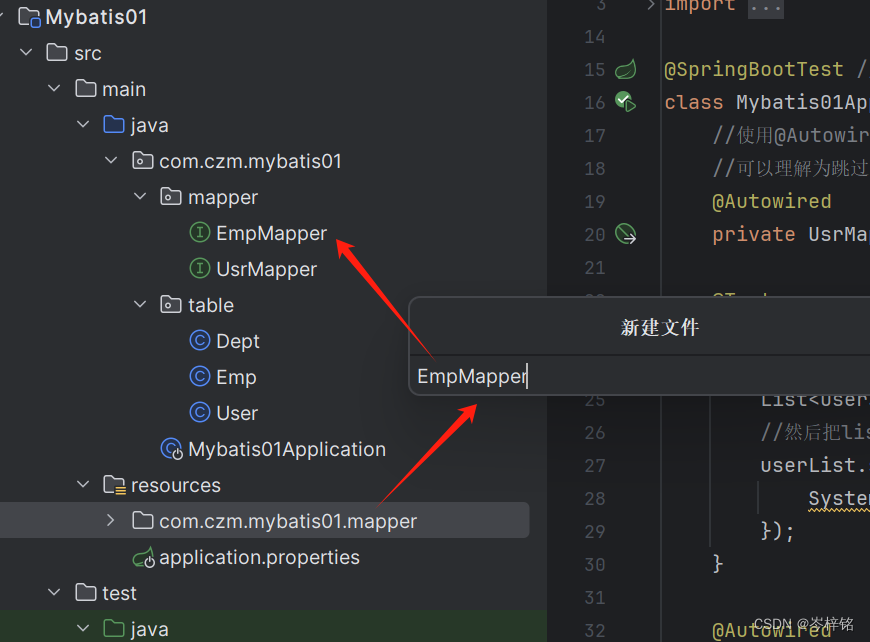
接着就到这个刚创建好的包里,新建XML文件,也是跟我们的Mapper里的接口要一样名
3、XML文件配置
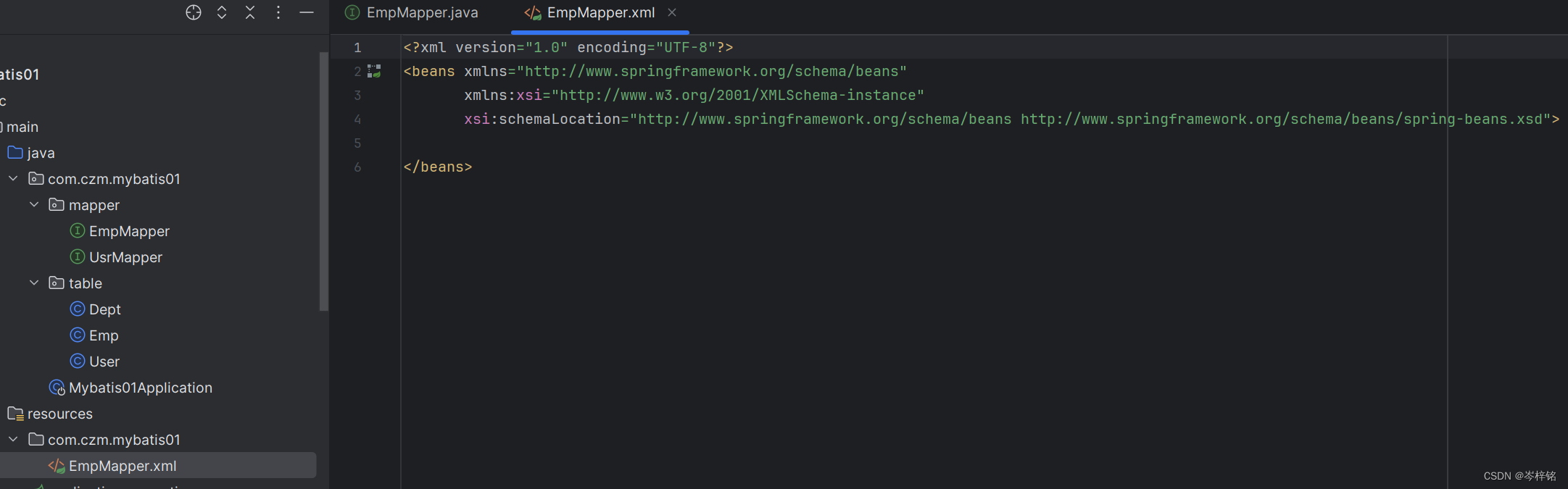
那么XML文件创建好之后,因为XML文件需要有一些约束,所以我们需要手动配到文件里
先把我们XML文件自带的这些原始代码删掉
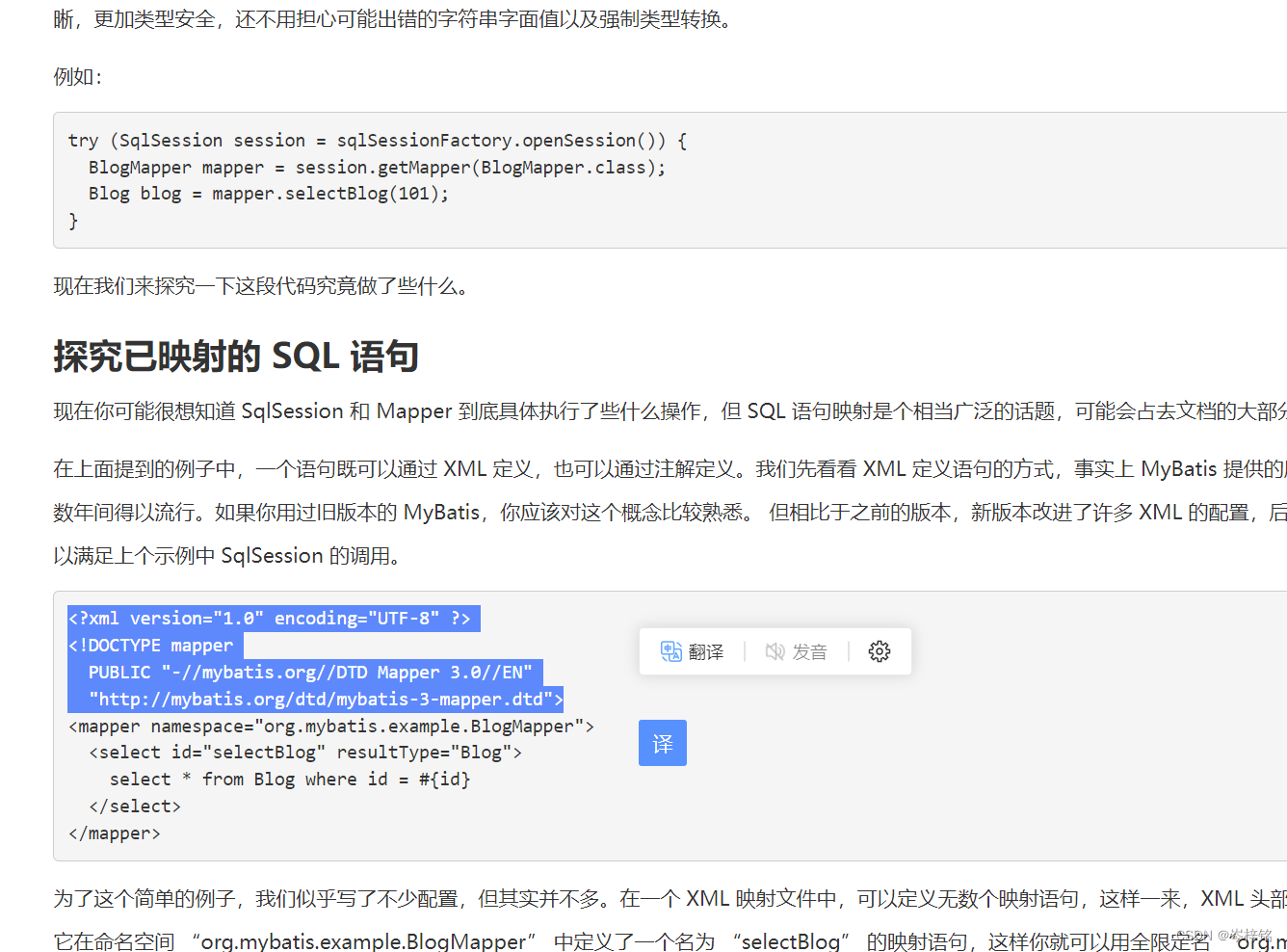
然后把下面的这段代码复制上XML文件最上面即可
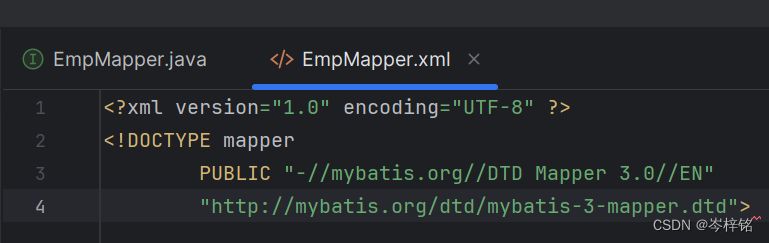
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">出自于Mybatis官网:入门_MyBatis中文网
然后我们就可在下面写一个双标签<mapper></mapper>,这里面就是执行所有sql语句操作的代码区
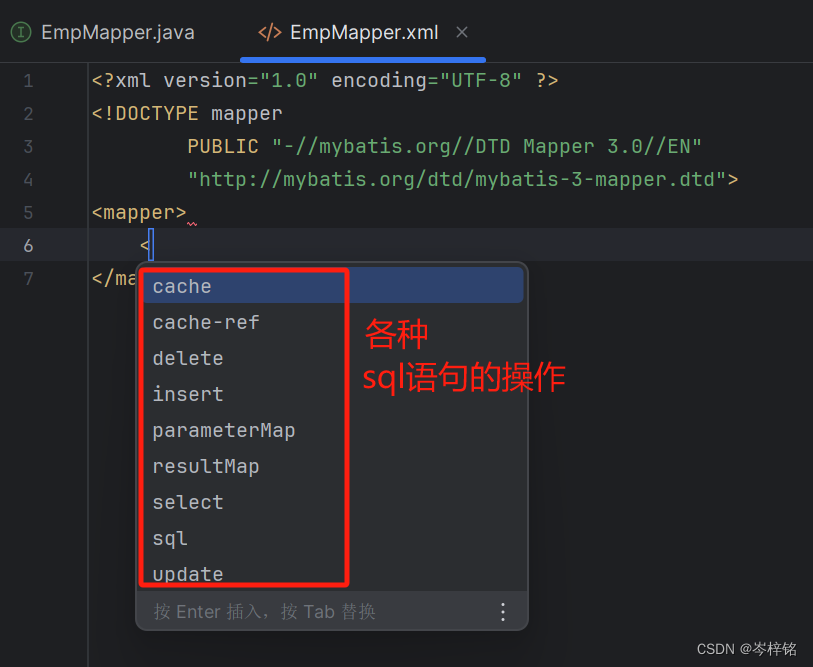
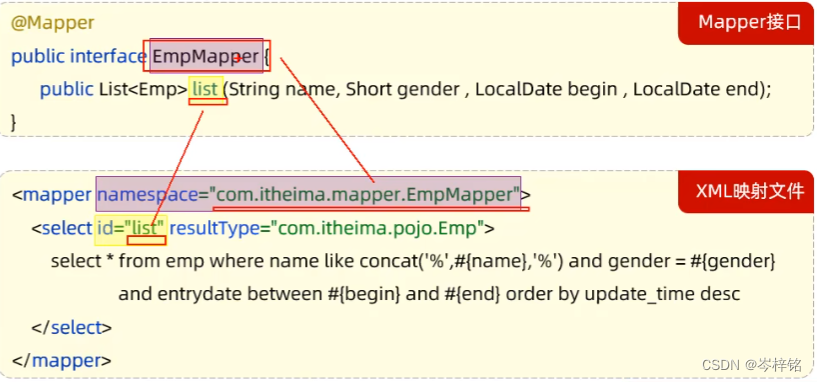
接下来我们要在<mapper>的namespace命名空间里绑定上是哪一个接口类名
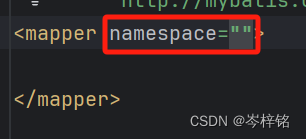
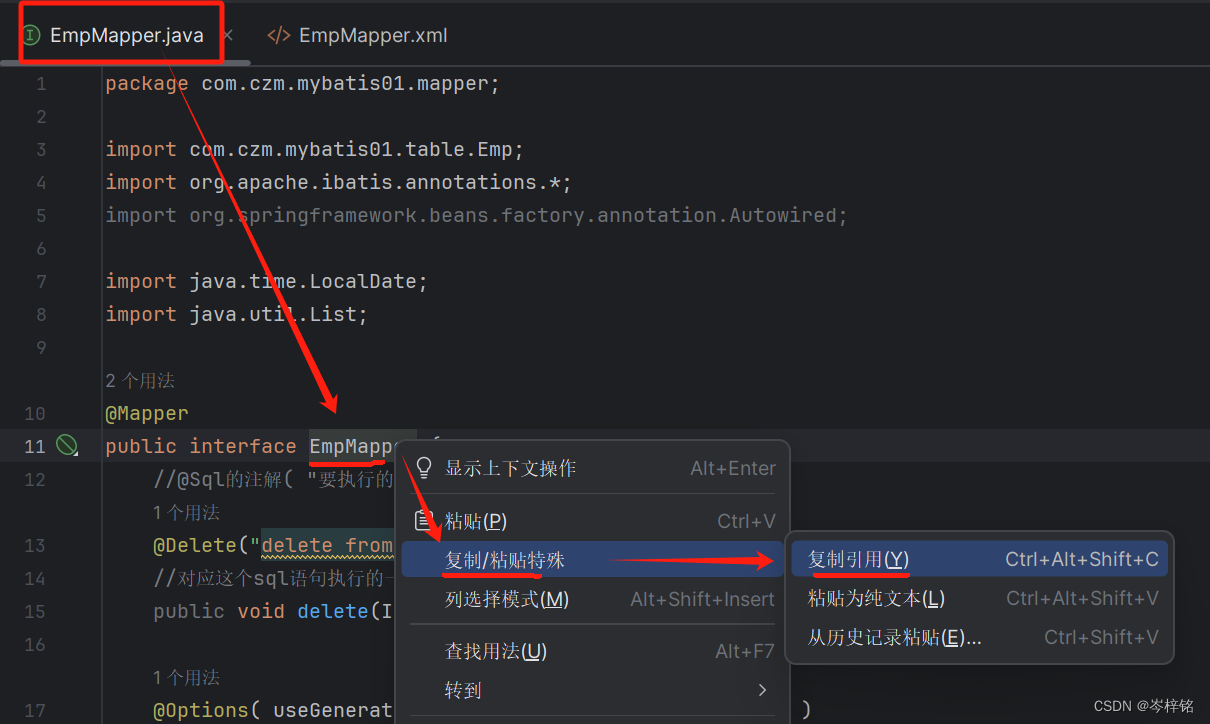
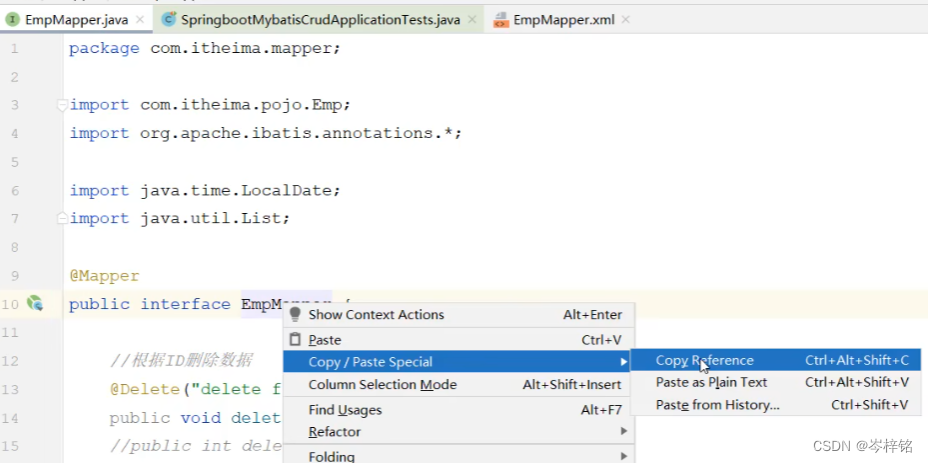
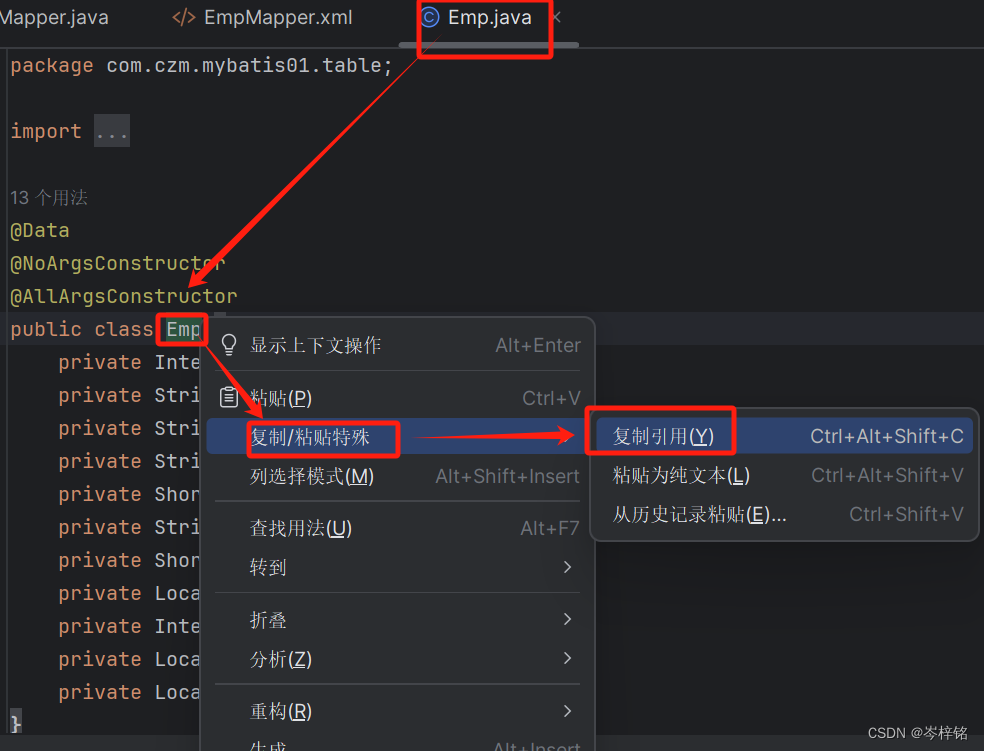
那接口类名去哪看?找到你要对于的接口,右键它的接口名,选“复制引用”
 中文
中文
 英文
英文
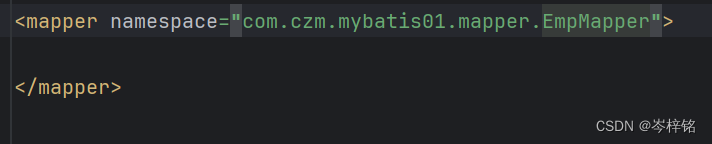
ok,现在<mapper></mapper>里可以执行sql语句操作了
4、怎么写sql语句?
要做什么操作,你就选什么标签
然后在里面写上对应sql的语句就行,其实跟@注解(sql语句)差不多,不过这些sql操作标签都有一个id属性,就是用来绑定原先对应注解的方法的方法名
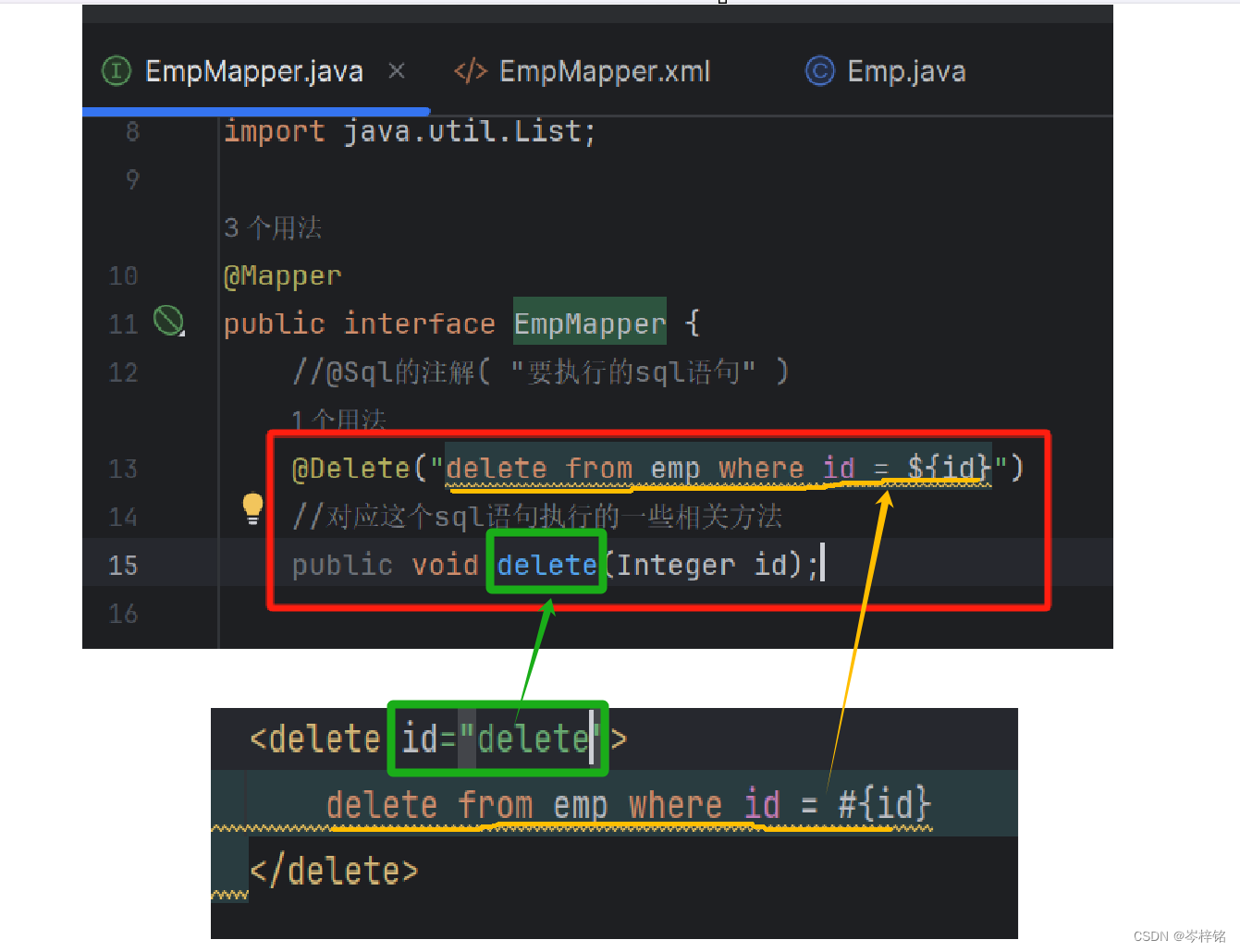
原先的@注解就可以注释掉了
如果像select这种操作,方法需要有返回值的,还得带上一个resultType,绑定的是【返回单条记录所封装的类型】,比如返回全部员工信息List<Emp>,那么单条信息就是Emp(全类名);加入返回的是一个员工对象Emp,那单条信息也就是Emp(全类名);
那么注意,不单单是一个类名就行,是全类名,全类名去到类的定义处,【复制引用】即可获得
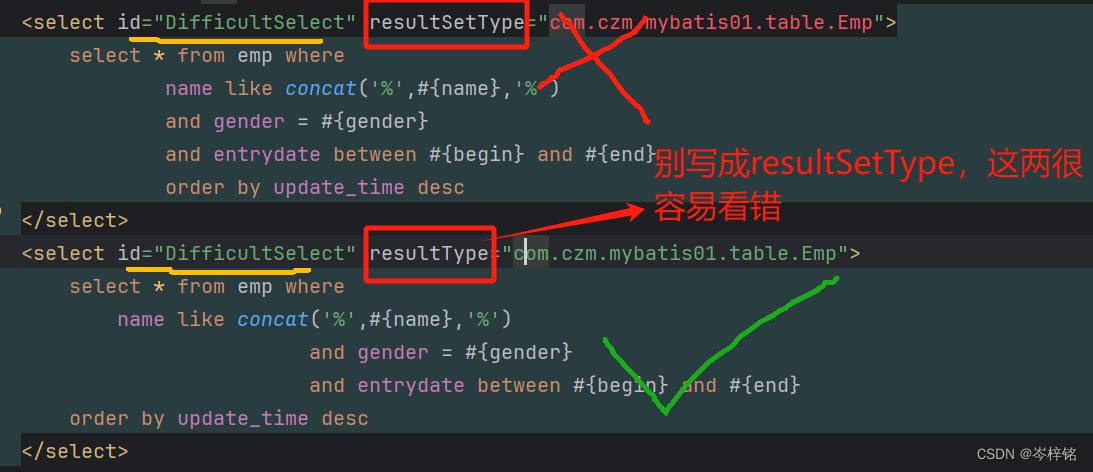
总结:这两种想用哪个用哪个,儿子对应关系如下图
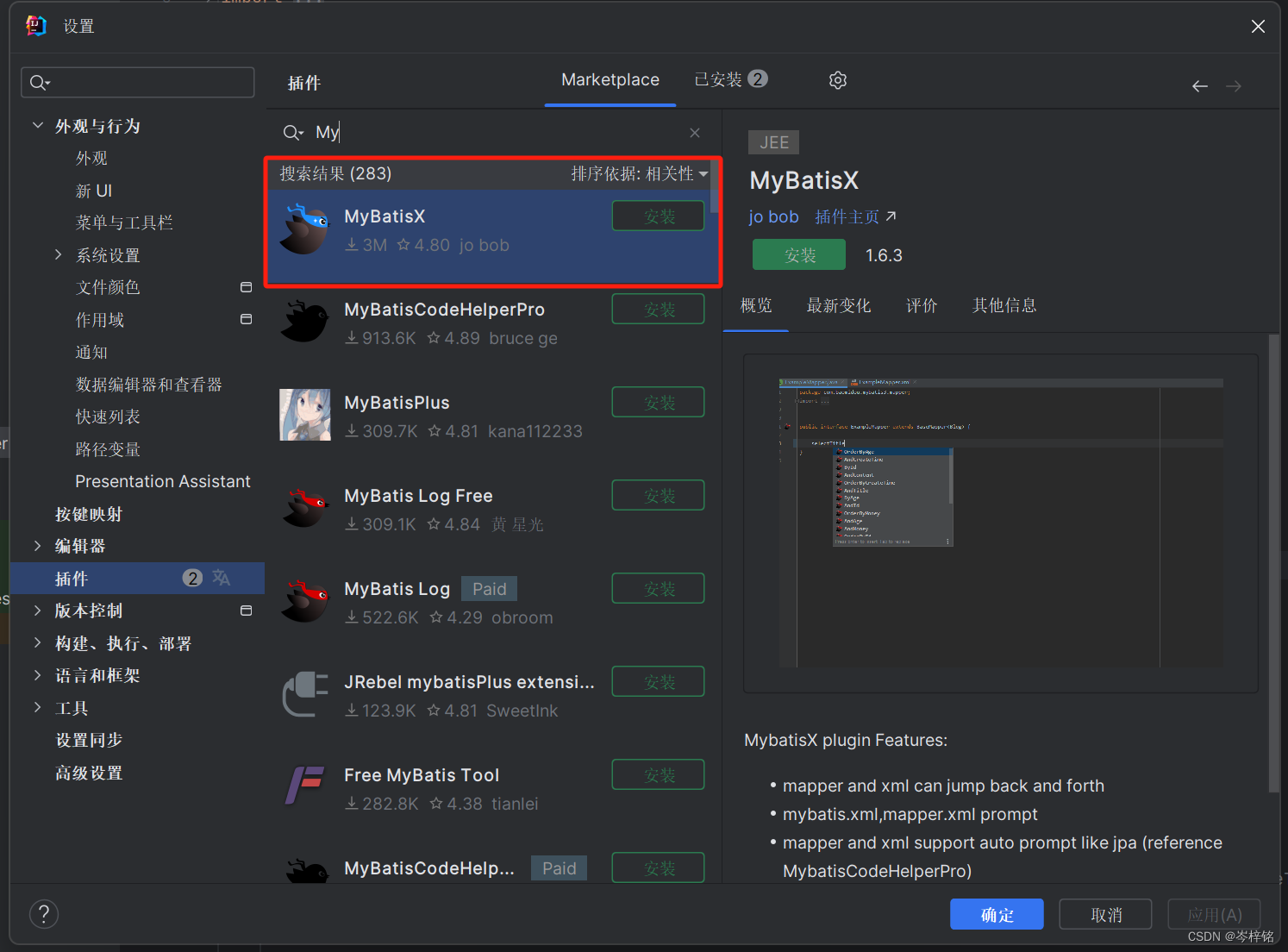
三、对应的高效插件:MyabtisX
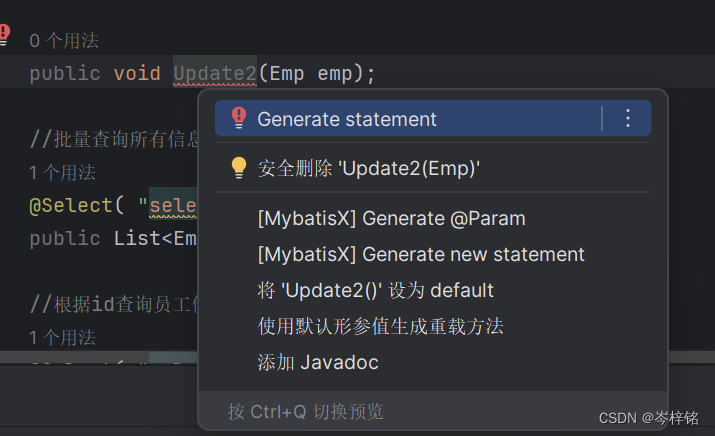
简单说,MybatisX就是能快速帮你跳到【对应某方法的sql语句的地方】,或者跳到【对应某sql语句的方法的地方】

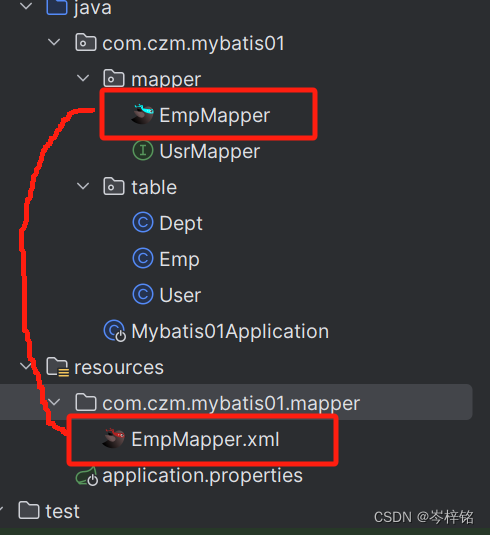

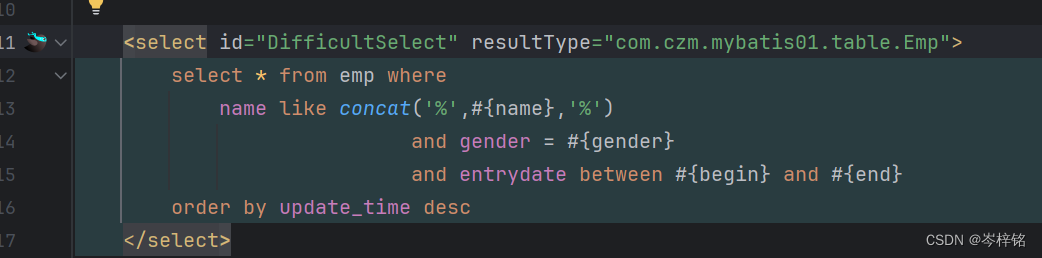
点一下就跳转了
还有一个好处,你在Mapper接口写好一个方法后,只要你的方法名里含有:select、update、delete、insert......这些sql操作的语句,那么摁下【Alt + 回车】就会有这么一个功能【Generrate statement】,点击会让你选择你要生成的对应的sql操作,选择一个就可以自动到XML文件里生成对应的sql代码区

感觉这一章其实没啥用,就简短写了