Hadoop学习笔记
作者: wayne1017
一、简要介绍
这里先大致介绍一下Hadoop.
本文大部分内容都是从官网Hadoop上来的。其中有一篇介绍HDFS的pdf文档,里面对Hadoop介绍的比较全面了。我的这一个系列的Hadoop学习笔记也是从这里一步一步进行下来的,同时又参考了网上的很多文章,对学习Hadoop中遇到的问题进行了归纳总结。
言归正传,先说一下Hadoop的来龙去脉。谈到Hadoop就不得不提到Lucene和Nutch。首先,Lucene并不是一个应用程序,而是提供了一个纯Java的高性能全文索引引擎工具包,它可以方便的嵌入到各种实际应用中实现全文搜索/索引功能。Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用,Lucene为Nutch提供了文本搜索和索引的API,Nutch不光有搜索的功能,还有数据抓取的功能。在nutch0.8.0版本之前,Hadoop还属于Nutch的一部分,而从nutch0.8.0开始,将其中实现的NDFS和MapReduce剥离出来成立一个新的开源项目,这就是Hadoop,而nutch0.8.0版本较之以前的Nutch在架构上有了根本性的变化,那就是完全构建在Hadoop的基础之上了。在Hadoop中实现了Google的GFS和MapReduce算法,使Hadoop成为了一个分布式的计算平台。
其实,Hadoop并不仅仅是一个用于存储的分布式文件系统,而是设计用来在由通用计算设备组成的大型集群上执行分布式应用的框架。
Hadoop包含两个部分:
1、HDFS
即Hadoop Distributed File System (Hadoop分布式文件系统)
HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode。
HDFS支持传统的层次文件组织结构,同现有的一些文件系统在操作上很类似,比如你可以创建和删除一个文件,把一个文件从一个目录移到另一个目录,重命名等等操作。Namenode管理着整个分布式文件系统,对文件系统的操作(如建立、删除文件和文件夹)都是通过Namenode来控制。
下面是HDFS的结构:
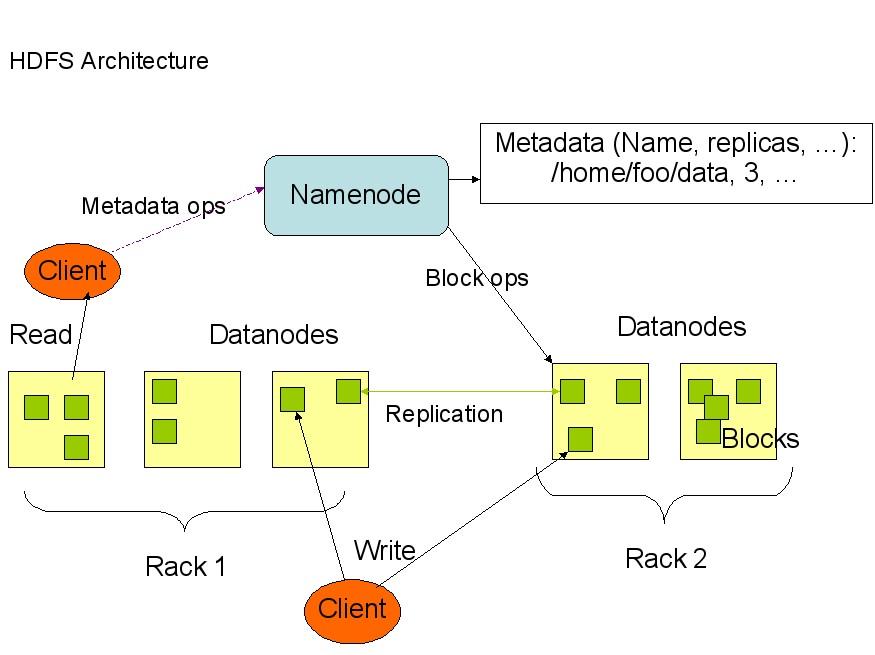
从上面的图中可以看出,Namenode,Datanode,Client之间的通信都是建立在TCP/IP的基础之上的。当Client要执行一个写入的操作的时候,命令不是马上就发送到Namenode,Client首先在本机上临时文件夹中缓存这些数据,当临时文件夹中的数据块达到了设定的Block的值(默认是64M)时,Client便会通知Namenode,Namenode便响应Client的RPC请求,将文件名插入文件系统层次中并且在Datanode中找到一块存放该数据的block,同时将该Datanode及对应的数据块信息告诉Client,Client便这些本地临时文件夹中的数据块写入指定的数据节点。
HDFS采取了副本策略,其目的是为了提高系统的可靠性,可用性。HDFS的副本放置策略是三个副本,一个放在本节点上,一个放在同一机架中的另一个节点上,还有一个副本放在另一个不同的机架中的一个节点上。当前版本的hadoop0.12.0中还没有实现,但是正在进行中,相信不久就可以出来了。
2、MapReduce的实现
MapReduce是Google 的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
MapReduce的名字源于这个模型中的两项核心操作:Map和 Reduce。也许熟悉Functional Programming(函数式编程)的人见到这两个词会倍感亲切。简单的说来,Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定,比如对[1, 2, 3, 4]进行乘2的映射就变成了[2, 4, 6, 8]。Reduce是对一组数据进行归约,这个归约的规则由一个函数指定,比如对[1, 2, 3, 4]进行求和的归约得到结果是10,而对它进行求积的归约结果是24。
关于MapReduce的内容,建议看看孟岩的这篇MapReduce:The Free Lunch Is Not Over!
好了,作为这个系列的第一篇就写这么多了,我也是刚开始接触Hadoop,下一篇就是讲Hadoop的部署,谈谈我在部署Hadoop时遇到的问题,也给大家一个参考,少走点弯路。
二、安装部署
本文主要是以安装和使用hadoop-0.12.0为例,指出在部署Hadoop的时候容易遇到的问题以及如何解决。
硬件环境
共有3台机器,均使用的FC5系统,Java使用的是jdk1.6.0。IP配置如下:
dbrg-1:202.197.18.72
dbrg-2:202.197.18.73
dbrg-3:202.197.18.74
这里有一点需要强调的就是,务必要确保每台机器的主机名和IP地址之间能正确解析。
一个很简单的测试办法就是ping一下主机名,比如在dbrg-1上ping dbrg-2,如果能ping通就OK!若不能正确解析,可以修改/etc/hosts文件,如果该台机器作Namenode用,则需要在hosts文件中加上集群中所有机器的IP地址及其对应的主机名;如果该台机器作Datanode用,则只需要在hosts文件中加上本机IP地址和Namenode机器的IP地址。
以本文为例,dbrg-1中的/etc/hosts文件看起来就应该是这样的:
127.0.0.0 localhost localhost
202.197.18.72 dbrg-1 dbrg-1
202.197.18.73 dbrg-2 dbrg-2
202.197.18.74 dbrg-3 dbrg-3
dbrg-2中的/etc/hosts文件看起来就应该是这样的:
127.0.0.0 localhost localhost
202.197.18.72 dbrg-1 dbrg-1
202.197.18.73 dbrg-2 dbrg-2
在上一篇学习笔记中提到过,对于Hadoop来说,在HDFS看来,节点分为Namenode和Datanode,其中Namenode只有一个,Datanode可以是很多;在MapReduce看来,节点又分为Jobtracker和Tasktracker,其中Jobtracker只有一个,Tasktracker可以是很多。
我是将namenode和jobtracker部署在dbrg-1上,dbrg-2,dbrg-3作为datanode和tasktracker。当然你也可以将namenode,datanode,jobtracker,tasktracker全部部署在一台机器上
目录结构
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
我的三台机器上是这样的:都有一个dbrg的帐户,主目录是/home/dbrg
Hadoop部署目录结构如下:/home/dbrg/HadoopInstall,所有的hadoop版本放在这个目录中。
将hadoop0.12.0压缩包解压至HadoopInstall中,为了方便以后升级,建议建立一个链接指向要使用的hadoop版本,不妨设为hadoop
[dbrg@dbrg-1:HadoopInstall]$ln -s hadoop0.12.0 hadoop
这样一来,所有的配置文件都在/hadoop/conf/目录中,所有执行程序都在/hadoop/bin目录中。
但是由于上述目录中hadoop的配置文件和hadoop的安装目录是放在一起的,这样一旦日后升级hadoop版本的时候所有的配置文件都会被覆盖,因此建议将配置文件与安装目录分离,一种比较好的方法就是建立一个存放配置文件的目录,/home/dbrg/HadoopInstall/hadoop-config/,然后将/hadoop/conf/目录中的hadoop_site.xml,slaves,hadoop_env.sh三个文件拷贝到hadoop-config/目录中(这个问题很奇怪,在官网上的Getting Started With Hadoop中说是只需要拷贝这个三个文件到自己创建的目录就可以了,但我在实际配置的时候发现还必须把masters这个文件也拷贝到hadoop-conf/目录中才行,不然启动Hadoop的时候就会报错说找不到masters这个文件),并指定环境变量$HADOOP_CONF_DIR指向该目录。环境变量在/home/dbrg/.bashrc和/etc/profile中设定。
综上所述,为了方便以后升级版本,我们需要做到配置文件与安装目录分离,并通过设定一个指向我们要使用的版本的hadoop的链接,这样可以减少我们对配置文件的维护。在下面的部分,你就会体会到这样分离以及链接的好处了。
SSH设置
在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个节点上的各种守护进程的,这就需要在节点之间执行指令的时候是不需要输入密码的方式,故我们需要配置SSH使用无密码公钥认证的方式。
首先要保证每台机器上都装了SSH服务器,且都正常启动。实际中我们用的都是OpenSSH,这是SSH协议的一个免费开源实现。FC5中默认安装的OpenSSH版本是OpenSSH4.3P2。
以本文中的三台机器为例,现在dbrg-1是主节点,它需要主动发起SSH连接到dbrg-2和dbrg-3,对于SSH服务来说,dbrg-1就是SSH客户端,而dbrg-2、dbrg-3则是SSH服务端,因此在dbrg-2,dbrg-3上需要确定sshd服务已经启动。简单的说,在dbrg-1上需要生成一个密钥对,即一个私钥,一个公钥。将公钥拷贝到dbrg-2,dbrg-3上,这样,比如当dbrg-1向dbrg-2发起ssh连接的时候,dbrg-2上就会生成一个随机数并用dbrg-1的公钥对这个随机数进行加密,并发送给dbrg-1;dbrg-1收到这个加密的数以后用私钥进行解密,并将解密后的数发送回dbrg-2,dbrg-2确认解密的数无误后就允许dbrg-1进行连接了。这就完成了一次公钥认证过程。
对于本文中的三台机器,首先在dbrg-1上生成密钥对:
[dbrg@dbrg-1:~]$ssh-keygen -t rsa
这个命令将为dbrg-1上的用户dbrg生成其密钥对,询问其保存路径时直接回车采用默认路径,当提示要为生成的密钥输入passphrase的时候,直接回车,也就是将其设定为空密码。生成的密钥对id_rsa,id_rsa.pub,默认存储在/home/dbrg/.ssh目录下。然后将id_rsa.pub的内容复制到每个机器(也包括本机)的/home/dbrg/.ssh/authorized_keys文件中,如果机器上已经有authorized_keys这个文件了,就在文件末尾加上id_rsa.pub中的内容,如果没有authorized_keys这个文件,直接cp或者scp就好了,下面的操作假设各个机器上都没有authorized_keys文件。
对于dbrg-1
[dbrg@dbrg-1:.ssh]$cp id_rsa.pub authorized_keys
对于dbrg-2(dbrg-3同dbrg-2的方法)
[dbrg@dbrg-2:~]$mkdir .ssh
[dbrg@dbrg-1:.ssh]$scp authorized_keys dbrg-2:/home/dbrg/.ssh/
此处的scp就是通过ssh进行远程copy,此处需要输入远程主机的密码,即dbrg-2机器上dbrg帐户的密码,当然,你也可以用其他方法将authorized_keys文件拷贝到其他机器上
[dbrg@dbrg-2:.ssh]$chmod 644 authorized_keys
这一步非常关键,必须保证authorized_keys只对其所有者有读写权限,其他人不允许有写的权限,否则SSH是不会工作的。我就曾经在配置SSH的时候郁闷了好久。
[dbrg@dbrg-2:.ssh]ls -la
drwx------ 2 dbrg dbrg .
drwx------ 3 dbrg dbrg ..
-rw-r--r-- 1 dbrg dbrg authorized_keys
注意每个机器上的.ssh目录的ls -la都应该和上面是一样的
接着,在三台机器上都需要对sshd服务进行配置(其实是可以不用配置的,完成了上面的那些操作了以后SSH就已经可以工作了),在三台机器上修改文件/etc/ssh/sshd_config
#去除密码认证
PasswordAuthentication no
AuthorizedKeyFile .ssh/authorized_keys
至此各个机器上的SSH配置已经完成,可以测试一下了,比如dbrg-1向dbrg-2发起ssh连接
[dbrg@dbrg-1:~]$ssh dbrg-2
如果ssh配置好了,就会出现以下提示信息
The authenticity of host [dbrg-2] can't be established.
Key fingerprint is 1024 5f:a0:0b:65:d3:82:df:ab:44:62:6d:98:9c:fe:e9:52.
Are you sure you want to continue connecting (yes/no)?
OpenSSH告诉你它不知道这台主机,但是你不用担心这个问题,因为你是第一次登录这台主机。键入“yes”。这将把这台主机的“识别标记”加到“~/.ssh/know_hosts”文件中。第二次访问这台主机的时候就不会再显示这条提示信息了。
然后你会发现不需要输入密码就可以建立ssh连接了,恭喜你,配置成功了
不过,别忘了测试本机ssh dbrg-1
Hadoop环境变量
在/home/dbrg/HadoopInstall/hadoop-conf目录下的hadoop_env.sh中设置Hadoop需要的环境变量,其中JAVA_HOME是必须设定的变量。HADOOP_HOME变量可以设定也可以不设定,如果不设定,HADOOP_HOME默认的是bin目录的父目录,即本文中的/home/dbrg/HadoopInstall/hadoop。我的是这样设置的
export HADOOP_HOME=/home/dbrg/HadoopInstall/hadoop
export JAVA_HOME=/usr/java/jdk1.6.0
从这个地方就可以看出前面所述的创建hadoop0.12.0的链接hadoop的优点了,当以后更新hadoop的版本的时候,就不需要在改配置文件,只需要更改链接就可以了。
Hadoop配置文件
如前所述,在hadoop-conf/目录下,打开slaves文件,该文件用来指定所有的从节点,一行指定一个主机名。即本文中的dbrg-2,dbrg-3,因此slaves文件看起来应该是这样的
dbrg-2
dbrg-3
在conf/目录中的hadoop-default.xml中包含了Hadoop的所有配置项,但是不允许直接修改!可以在hadoop-conf/目录下的hadoop-site.xml里面定义我们需要的项,其值会覆盖hadoop-default.xml中的默认值。可以根据自己的实际需要来进行定制。以下是我的配置档:
fs.default.name
dbrg-1:9000
The name of the default file system. Either the literal string "local" or a host:port for DFS.
mapred.job.tracker
dbrg-1:9001
The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task.
hadoop.tmp.dir
/home/dbrg/HadoopInstall/tmp
A base for other temporary directories.
dfs.name.dir
/home/dbrg/HadoopInstall/filesystem/name
Determines where on the local filesystem the DFS name node should store the name table. If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy.
dfs.data.dir
/home/dbrg/HadoopInstall/filesystem/data
Determines where on the local filesystem an DFS data node should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Directories that do not exist are ignored.
dfs.replication
1
Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time.
部署Hadoop
前面讲的这么多Hadoop的环境变量和配置文件都是在dbrg-1这台机器上的,现在需要将hadoop部署到其他的机器上,保证目录结构一致。
[dbrg@dbrg-1:~]$scp -r /home/dbrg/HadoopInstall dbrg-2:/home/dbrg/
[dbrg@dbrg-1:~]$scp -r /home/dbrg/HadoopInstall dbrg-3:/home/dbrg/
至此,可以说,Hadoop已经在各个机器上部署完毕了下面就让我们开始启动Hadoop吧
启动Hadoop
启动之前,我们先要格式化namenode,先进入~/HadoopInstall/hadoop目录,执行下面的命令
[dbrg@dbrg-1:hadoop]$bin/hadoop namenode -format
不出意外,应该会提示格式化成功。如果不成功,就去hadoop/logs/目录下去查看日志文件
下面就该正式启动hadoop啦,在bin/下面有很多启动脚本,可以根据自己的需要来启动。
* start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
* stop-all.sh 停止所有的Hadoop
* start-mapred.sh 启动Map/Reduce守护。包括Jobtracker和Tasktrack
* stop-mapred.sh 停止Map/Reduce守护
* start-dfs.sh 启动Hadoop DFS守护.Namenode和Datanode
* stop-dfs.sh 停止DFS守护
在这里,简单启动所有守护
[dbrg@dbrg-1:hadoop]$bin/start-all.sh
同样,如果要停止hadoop,则
[dbrg@dbrg-1:hadoop]$bin/stop-all.sh
HDFS操作
运行bin/目录的hadoop命令,可以查看Haoop所有支持的操作及其用法,这里以几个简单的操作为例。
建立目录
[dbrg@dbrg-1:hadoop]$bin/hadoop dfs -mkdir testdir
在HDFS中建立一个名为testdir的目录
复制文件
[dbrg@dbrg-1:hadoop]$bin/hadoop dfs -put /home/dbrg/large.zip testfile.zip
把本地文件large.zip拷贝到HDFS的根目录/user/dbrg/下,文件名为testfile.zip
查看现有文件
[dbrg@dbrg-1:hadoop]$bin/hadoop dfs -ls
来源:
http://www.cnblogs.com/wayne1017/archive/2007/03/18/668768.html
http://www.cnblogs.com/wayne1017/archive/2007/03/20/678724.html
![[原创] 推荐介绍几款小巧的Web Server程序](/images/no-images.jpg)


